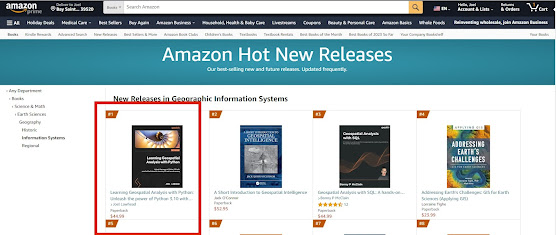
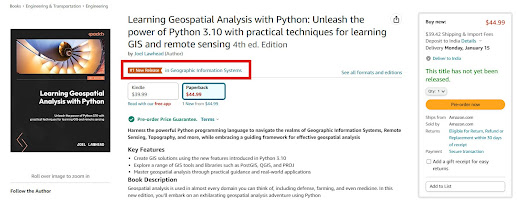
🚀 Exciting News!! 📚 The 10-year anniversary edition of 🌎 "Learning Geospatial Analysis with Python - 4th Ed," 🐍 is now available on Amazon and it's starting off on fire 🔥 as #1 in the GIS New Release category! 🥇
Thank you to all of my fellow geography-obsessed and Python-loving friends out there for making this book possible. In this edition, I'll help you up your geospatial game with package management in Anaconda and new data types including bathymetric point clouds so you can explore the ocean. Even more exciting I'll show you how to speed up your workflow by using ChatGPT as a tireless geospatial programming assistant.I bring you up to speed on the entire history of geospatial analysis and then lead you through concepts and major software tools, and then teach you simple geospatial algorithms that will serve as building blocks for the complete programs that come later in the book.
These examples are designed to teach people new to Python and geospatial analysis, but are built to empower experienced practitioners as well with code that you will use everyday for common GIS challenges.
Grab 🖐 your copy 📖 today and start changing the world by analyzing it using one of the most popular programming languages ever created!
https://a.co/d/atLzCEc